如果已安装metrics-server需要先卸载,否则冲突
组件说明
---
- MetricServer:是kubernetes集群资源使用情况的聚合器,收集数据给kubernetes集群内使用,如kubectl,hpa,scheduler等。
- PrometheusOperator:是一个系统监测和警报工具箱,用来存储监控数据。
- NodeExporter:用于各node的关键度量指标状态数据。
- KubeStateMetrics:收集kubernetes集群内资源对象数据,制定告警规则。
- Prometheus:采用pull方式收集apiserver,scheduler,controller-manager,kubelet组件数据,通过http协议传输。
- Grafana:是可视化数据统计和监控平台。
安装部署
---
项目地址:https://github.com/prometheus-operator/kube-prometheus
克隆项目至本地
---
1
| git clone https://github.com/prometheus-operator/kube-prometheus.git
|
创建资源对象
---
1
2
3
4
5
6
7
8
| [root@master1 k8s-install]# kubectl create namespace monitoring
[root@master1 k8s-install]# cd kube-prometheus/
[root@master1 kube-prometheus]# kubectl apply --server-side -f manifests/setup
[root@master1 kube-prometheus]# kubectl wait \
--for condition=Established \
--all CustomResourceDefinition \
--namespace=monitoring
[root@master1 kube-prometheus]# kubectl apply -f manifests/
|
验证查看
---
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| [root@master1 kube-prometheus]# kubectl get pod -n monitoring
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 2/2 Running 0 61s
alertmanager-main-1 2/2 Running 0 61s
alertmanager-main-2 2/2 Running 0 61s
blackbox-exporter-576df9484f-lr6xd 3/3 Running 0 107s
grafana-795ddfd4bd-jxlrw 1/1 Running 0 105s
kube-state-metrics-bdfdcd5cd-7dgwl 3/3 Running 0 104s
node-exporter-4qnrz 2/2 Running 0 104s
node-exporter-8hjr7 2/2 Running 0 104s
node-exporter-8s5hp 2/2 Running 0 103s
node-exporter-kgb48 2/2 Running 0 104s
node-exporter-p8b7q 2/2 Running 0 103s
node-exporter-v4nz7 2/2 Running 0 103s
prometheus-adapter-65b6bd474c-qvdb8 1/1 Running 0 102s
prometheus-adapter-65b6bd474c-vlxhn 1/1 Running 0 102s
prometheus-k8s-0 1/2 Running 0 58s
prometheus-k8s-1 2/2 Running 0 58s
prometheus-operator-6565b7b5f5-mgclf 2/2 Running 0 101s
|
1
2
3
4
5
6
7
8
9
10
11
12
13
| [root@master1 kube-prometheus]# kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
master1 579m 14% 2357Mi 66%
master2 383m 9% 1697Mi 48%
master3 482m 12% 2069Mi 58%
work1 131m 3% 1327Mi 37%
work2 132m 3% 1134Mi 32%
work3 176m 4% 1100Mi 31%
[root@master1 kube-prometheus]# kubectl top pod
NAME CPU(cores) MEMORY(bytes)
myapp-58bbc79c4f-cc9g5 0m 1Mi
myapp-58bbc79c4f-txnp5 0m 1Mi
myapp-58bbc79c4f-zvlcr 0m 1Mi
|
新增ingress资源
---
以ingress-nginx为例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
| [root@master1 manifests]# cat ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: alertmanager
namespace: monitoring
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
ingressClassName: nginx
rules:
- host: alertmanager.local.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: alertmanager-main
port:
number: 9093
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: grafana
namespace: monitoring
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
ingressClassName: nginx
rules:
- host: grafana.local.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: grafana
port:
number: 3000
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: prometheus
namespace: monitoring
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
ingressClassName: nginx
rules:
- host: prometheus.local.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: prometheus-k8s
port:
number: 9090
|
web访问验证
---
1
| 192.168.10.10 alertmanager.local.com grafana.local.com prometheus.local.com
|
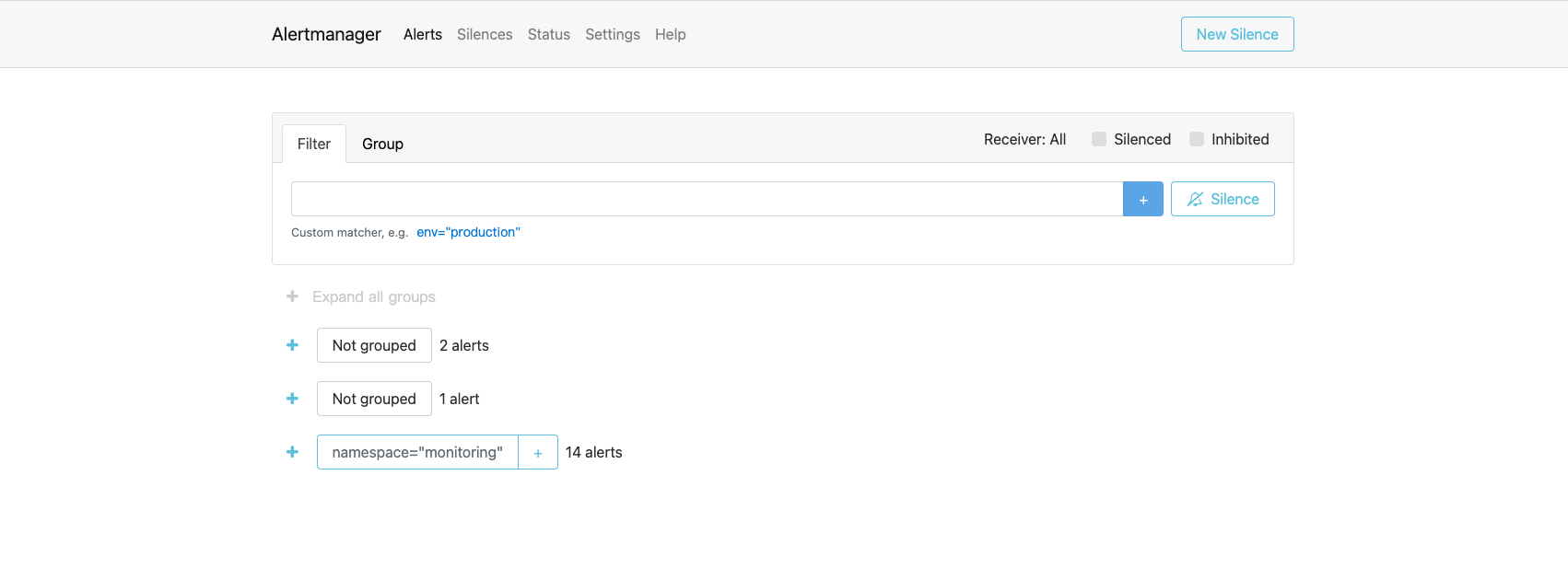
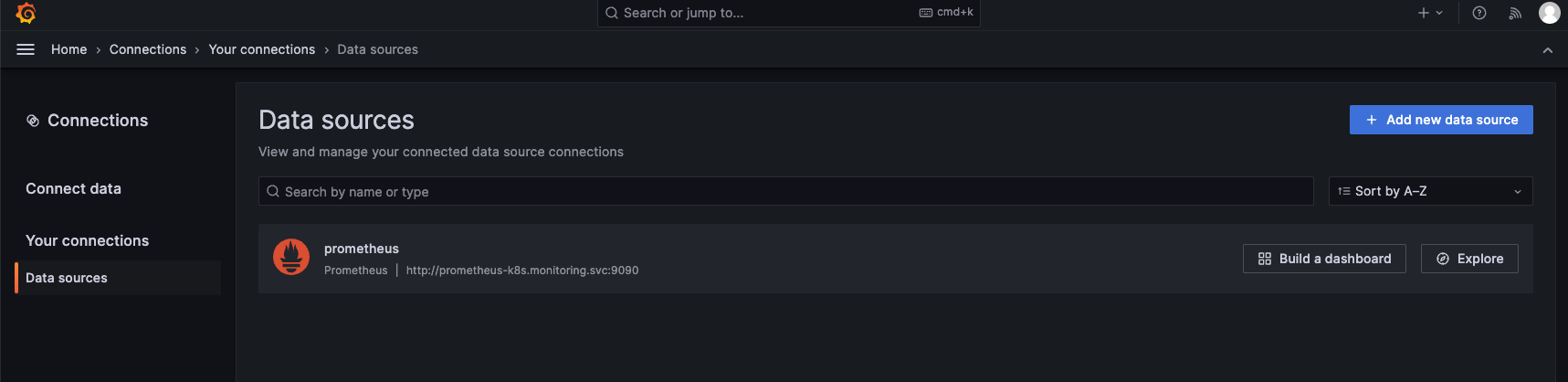
- 查看数据源,以为我们自动配置Prometheus数据源
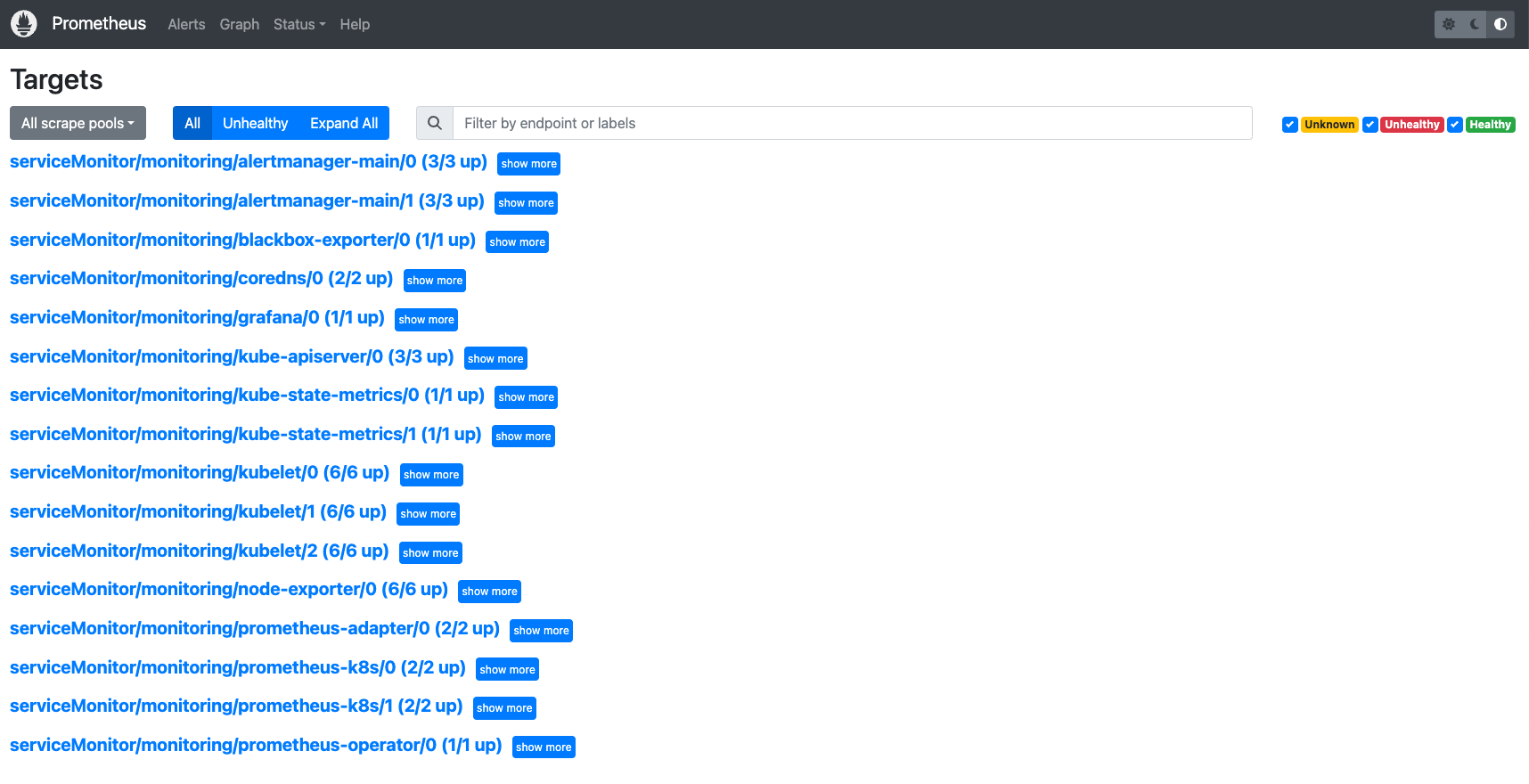
targets异常处理
---
查看targets可发现有两个监控任务没有对应的instance,这和serviceMonitor资源对象有关
由于prometheus-serviceMonitorKubeScheduler文件中,selector匹配的是service的标签,但是namespace中并没有app.kubernetes.io/name的service
- 新建prometheus-kubeSchedulerService.yaml并apply创建资源
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-scheduler
labels:
app.kubernetes.io/name: kube-scheduler
spec:
selector:
component: kube-scheduler
type: ClusterIP
ports:
- name: https-metrics
port: 10259
targetPort: 10259
protocol: TCP
|
- 新建prometheus-kubeControllerManagerService.yaml并apply创建资源
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-controller-manager
labels:
app.kubernetes.io/name: kube-controller-manager
spec:
selector:
component: kube-controller-manager
type: ClusterIP
ports:
- name: https-metrics
port: 10257
targetPort: 10257
protocol: TCP
|
- 再次查看targets信息
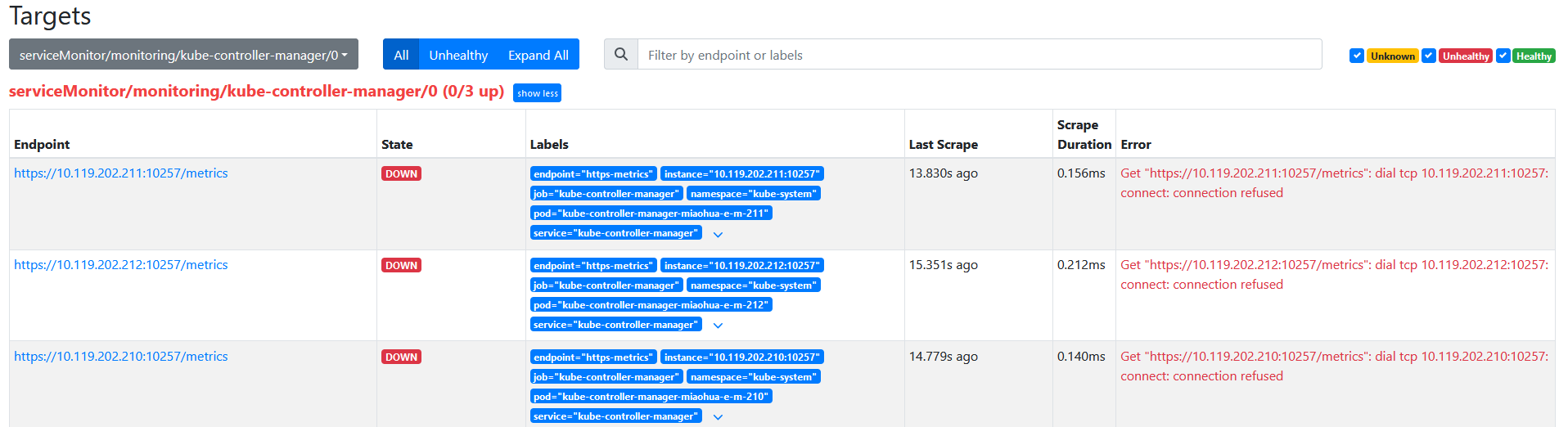
发现虽然加载了targets,但是无法访问该端口。
需要请修改master节点的/etc/kubernetes/manifests/kube-controller-manager.yaml 文件和 /etc/kubernetes/manifests/kube-scheduler.yaml 文件,将其中的 - –bind-address=127.0.0.1 修改为 - –bind-address=0.0.0.0
修改完保存文件,pod会自动重启。
部署pushgateway(可选)
---
创建资源清单
---
pushgateway目录下,创建这三个yaml文件。
- prometheus-pushgatewayServiceMonitor.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
prometheus: k8s
name: prometheus-pushgateway
namespace: monitoring
spec:
endpoints:
- honorLabels: true
port: http
jobLabel: pushgateway
selector:
matchLabels:
app: prometheus-pushgateway
|
- prometheus-pushgatewayService.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| apiVersion: v1
kind: Service
metadata:
labels:
app: prometheus-pushgateway
name: prometheus-pushgateway
namespace: monitoring
spec:
type: NodePort
ports:
- name: http
port: 9091
nodePort: 30400
targetPort: metrics
selector:
app: prometheus-pushgateway
# type: ClusterIP
|
- prometheus-pushgatewayDeployment.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: prometheus-pushgateway
name: prometheus-pushgateway
namespace: monitoring
spec:
replicas: 1
selector:
matchLabels:
app: prometheus-pushgateway
template:
metadata:
labels:
app: prometheus-pushgateway
spec:
containers:
- image: prom/pushgateway:v1.10.0
livenessProbe:
httpGet:
path: /#/status
port: 9091
initialDelaySeconds: 10
timeoutSeconds: 10
name: prometheus-pushgateway
ports:
- containerPort: 9091
name: metrics
readinessProbe:
httpGet:
path: /#/status
port: 9091
initialDelaySeconds: 10
timeoutSeconds: 10
resources:
limits:
cpu: 50m
memory: 100Mi
requests:
cpu: 50m
memory: 100Mi
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| apiVersion: traefik.io/v1alpha1
kind: IngressRoute
metadata:
name: prometheus-pushgateway
namespace: monitoring
spec:
entryPoints:
- web
routes:
- match: Host(`prometheus-pushgateway.local.com`)
kind: Rule
services:
- name: prometheus-pushgateway
port: 9091
|
创建资源
---
查看验证
---
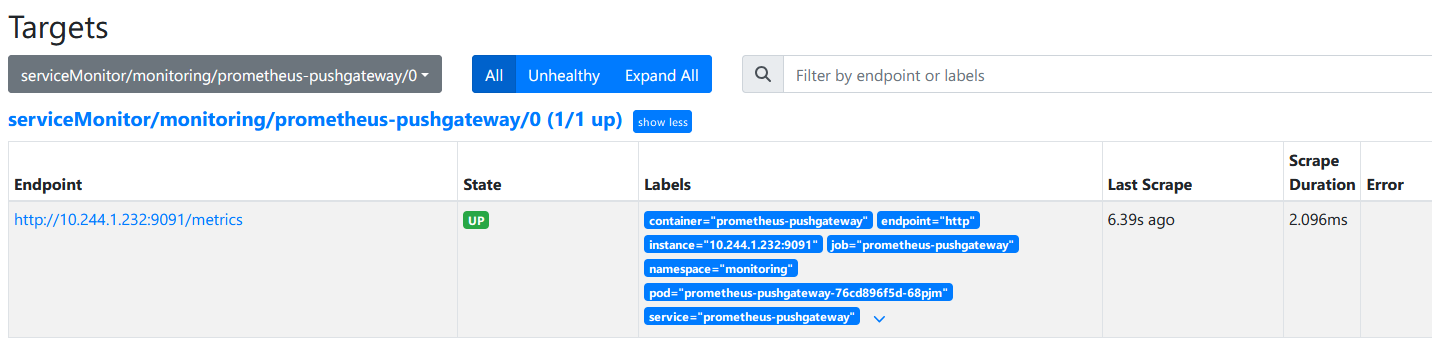
高级配置
---
Grafana配置修改
---
默认grafana使用UTC时区和sqllite数据库,可按需调整
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| # pwd
/opt/k8s/kube-prometheus/manifests
# cat grafana-config.yaml
apiVersion: v1
kind: Secret
metadata:
labels:
app.kubernetes.io/component: grafana
app.kubernetes.io/name: grafana
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 11.2.1
name: grafana-config
namespace: monitoring
stringData:
grafana.ini: |
[date_formats] # 时区设置
default_timezone = Asia/Shanghai
[database] # 数据库设置
type = mysql
host = cluster-mysql-master.mysql.svc:3306
name = grafana
user = grafana
password = password
type: Opaque
|
数据持久化存储
---
默认的的存储为<font style="background-color:rgba(255, 255, 255, 0);">emptyDir</font>,生产环境建议更换为<font style="background-color:rgba(255, 255, 255, 0);">persistentVolumeClaim</font>
创建grafana-pvc
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| # cat grafana-pvc.yaml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: grafana-pvc
namespace: monitoring
spec:
storageClassName: nfs
accessModes:
- ReadWriteMany
resources:
requests:
storage: 500Mi
# kubectl apply -f grafana-pvc.yaml
persistentvolumeclaim/grafana-pvc created
|
修改grafana
1
2
3
4
5
6
7
8
| # cp /opt/k8s/kube-prometheus/manifests/grafana-deployment.yaml .
# vim grafana-deployment.yaml
volumes:
- name: grafana-storage
persistentVolumeClaim:
claimName: grafana-pvc
# kubectl apply -f grafana-deployment.yaml
deployment.apps/grafana configured
|
修改prometheus
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| # cp /opt/k8s/kube-prometheus/manifests/prometheus-prometheus.yaml .
# vim prometheus-prometheus.yaml
spec:
image: quay.io/prometheus/prometheus:v2.54.1
retention: 30d # 数据保留天数
storage: # 持久化配置
volumeClaimTemplate:
spec:
storageClassName: nfs
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 500Gi
# kubectl apply -f prometheus-prometheus.yaml
prometheus.monitoring.coreos.com/k8s configured
|
node exporter新增ip标签
---
默认情况下node exporter指标只有主机名没有ip标签,可添加全局IP标签。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| # cp ../kube-prometheus/manifests/nodeExporter-serviceMonitor.yaml .
# vim nodeExporter-serviceMonitor.yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: node-exporter
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 1.8.2
name: node-exporter
namespace: monitoring
spec:
endpoints:
- bearerTokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token
interval: 15s
port: https
relabelings:
- action: replace
regex: (.*)
replacement: $1
sourceLabels:
- __meta_kubernetes_pod_node_name
targetLabel: instance
- action: replace
sourceLabels:
- __meta_kubernetes_pod_host_ip
targetLabel: ip
scheme: https
tlsConfig:
insecureSkipVerify: true
jobLabel: app.kubernetes.io/name
selector:
matchLabels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: node-exporter
app.kubernetes.io/part-of: kube-prometheus
|

