存储基础
基础知识
---存储方式介绍
---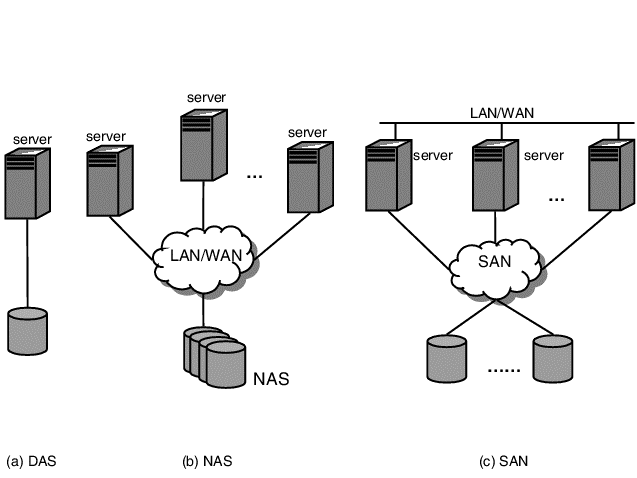
直连附加存储(DAS)
定义:DAS 指Direct Attached Storage,即直连附加存储,可以理解为本地文件系统。这种设备直接连接到计算机主板总线上,计算机将其识别为一个块设备,例如常见的硬盘,U盘等,这种设备很难做到共享。特点:DAS 购置成本低,配置简单,使用过程和使用本机硬盘并无太大差别,对于服务器的要求仅仅是一个外接的<font style="background-color:rgba(255, 255, 255, 0);">SCSI</font>口,因此对于小型企业很有吸引力。
缺点:
(1) 数据备份操作复杂。
(2) 服务器本身容易成为系统瓶颈。
(3) 服务器发生故障,数据不可访问。
(4) 对于存在多个服务器的系统来说,设备分散,不便管理。
网络附加存储(NAS)
定义:NAS指Network Area Storage,即网络附加存储。它一般是将本地的存储空间共享给其他主机使用,一般通过C/S架构实现通信。它实现的是文件级别的共享,计算机通常将共享的设别识别为一个文件系统,其文件服务器会管理锁以实现并发访问。网络文件系统,以文件模块的形式进行共享,工作在应用层上,常见的NAS有NFS和CIFS(FTP)。特点:NAS实际是一种带有瘦服务器的存储设备,这个瘦服务器实际是一台网络文件服务器。NAS设备直接连接到TCP/IP网络上,网络服务器通过TCP/IP网络存取管理数据。NAS作为一种瘦服务器系统,易于安装和部署,管理使用也很方便。
缺点:
(1) 存储数据通过网络传输,因此容易产生数据泄漏等安全问题。
(2) 存储数据通过网络传输,因此易受网络上其它流量的影响,当网络上有其它大数据流量时会严重影响系统性能。
(3) 存储只能以文件方式访问,而不能像普通文件系统一样直接访问物理数据块,因此会在某些情况下严重影响系统效率,比如大型数据库就不能使用 NAS 这种存储方案。
存储区域网(SAN)
定义:`SAN`指Storage Area Network,即`存储区域网络`,工作于内核层。它将传输网络模拟成`SCSI`总线来使用,每一个主机的网卡相当于SCSI总线中的initiator,服务器相当于一个或多个target,它需要借助客户端和服务端的SCSI驱动,通过FC或TCP/IP协议封装SCSI报文。它实现的是`块级别`的共享,通常被识别为一个块设备,但是需要借助专门的锁管理软件才能实现多主机并发访问。特点:SAN实际是一种专门为存储建立的独立于TCP/IP网络之外的专用网络。目前一般的SAN提供2Gb/S到4Gb/S的传输数率,同时SAN网络独立于数据网络存在,因此存取速度很快,另外SAN一般采用高端的RAID阵列,使SAN的性能在几种专业网络存储技术中傲视群雄。SAN由于其基础是一个专用网络,因此扩展性很强,不管是在一个SAN系统中增加一定的存储空间还是增加几台使用存储空间的服务器都非常方便。
缺点:
(1) 需要单独建立光纤网络,异地扩展比较困难。
(2) 不论是SAN阵列柜还是SAN必须的光纤通道交换机价格都是十分昂贵的。
存储方式对比
---| DAS | NAS | IP-SAN | FC-SAN | |
|---|---|---|---|---|
| 成本 | 低 | 较低 | 较高 | 高 |
| 数据传输速度 | 快 | 慢 | 较快 | 极快 |
| 扩展性 | 无扩展性 | 较低 | 最易扩展 | 易于扩展 |
| 服务器访问存储方式 | 直接访问存储数据块 | 以文件方式访问 | 直接访问存储数据块 | 直接访问存储数据块 |
| 服务器系统性能开销 | 低 | 较低 | 较高 | 低 |
| 安全性 | 高 | 低 | 低 | 高 |
| 是否集中管理存储 | 否 | 是 | 是 | 是 |
| 备份效率 | 低 | 较低 | 较高 | 高 |
| 网络传输协议 | 无 | TCP/IP | TCP/IP | Fibre Channel |
文件系统
---文件系统的基本组成
---文件系统是操作系统中负责管理持久数据的子系统,负责把用户的文件存到磁盘硬件中。
文件系统的基本数据单位是文件,它的目的是对磁盘上的文件进行组织管理,那组织的方式不同,就会形成不同的文件系统。
Linux 文件系统会为每个文件分配两个数据结构:索引节点(index node)和目录项(directory entry),它们主要用来记录文件的元信息和目录层次结构。
索引节点
也就是 inode,用来记录文件的元信息,比如 inode 编号、文件大小、访问权限、创建时间、修改时间、数据在磁盘的位置等等。索引节点是文件的唯一标识,它们之间一一对应,也同样都会被存储在硬盘中,所以索引节点同样占用磁盘空间。目录项
也就是 dentry,用来记录文件的名字、索引节点指针以及与其他目录项的层级关联关系。多个目录项关联起来,就会形成目录结构,但它与索引节点不同的是,目录项是由内核维护的一个数据结构,不存放于磁盘,而是缓存在内存。由于索引节点唯一标识一个文件,而目录项记录着文件的名,所以目录项和索引节点的关系是多对一,也就是说,一个文件可以有多个别字。比如,硬链接的实现就是多个目录项中的索引节点指向同一个文件。
目录也是文件,也是用索引节点唯一标识,和普通文件不同的是,普通文件在磁盘里面保存的是文件数据,而目录文件在磁盘里面保存子目录或文件。
如果查询目录频繁从磁盘读,效率会很低,所以内核会把已经读过的目录用目录项这个数据结构缓存在内存,下次再次读到相同的目录时,只需从内存读就可以,大大提高了文件系统的效率。
数据存储过程
---磁盘读写的最小单位是扇区,扇区的大小只有 512B 大小,很明显,如果每次读写都以这么小为单位,那这读写的效率会非常低。所以,文件系统把多个扇区组成了一个逻辑块,每次读写的最小单位就是逻辑块(数据块),Linux 中的逻辑块大小为 4KB,也就是一次性读写 8 个扇区,这将大大提高了磁盘的读写的效率。
索引节点是存储在硬盘上的数据,那么为了加速文件的访问,通常会把索引节点加载到内存中。
磁盘想要呗文件系统使用,需要进行格式化,在格式化的时候,会被分成三个存储区域,分别是超级块、索引节点区和数据块区。
超级块
用来存储文件系统的详细信息,比如块个数、块大小、空闲块等等。索引节点区
用来存储索引节点,也就是记录文件的属性等元信息。数据块区
用来存储文件或目录数据。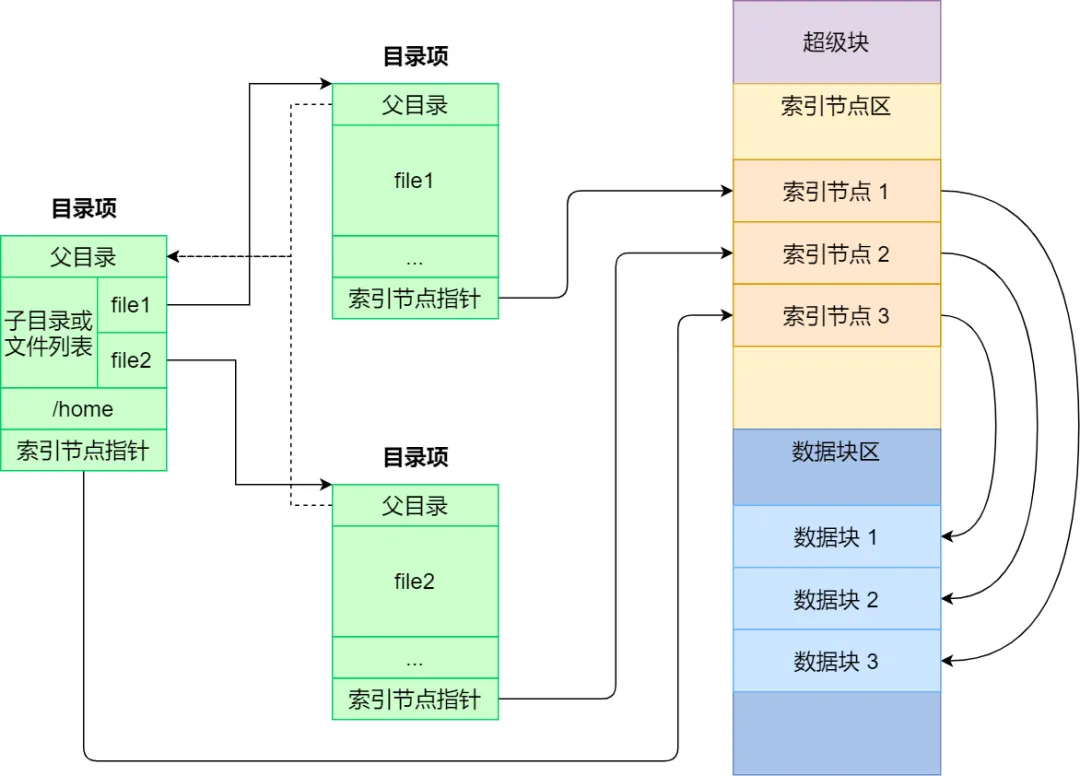
我们不可能把超级块和索引节点区全部加载到内存,这样内存肯定撑不住,所以只有当需要使用的时候,才将其加载进内存,它们加载进内存的时机是不同的:
超级块:当文件系统挂载时进入内存;
索引节点区:当文件被访问时进入内存;
虚拟文件系统
---文件系统的种类众多,而操作系统希望对用户提供一个统一的接口,于是在用户层与文件系统层引入了中间层,这个中间层就称为虚拟文件系统(Virtual File System,VFS)。
VFS 定义了一组所有文件系统都支持的数据结构和标准接口,这样程序员不需要了解文件系统的工作原理,只需要了解 VFS 提供的统一接口即可。
在 Linux 文件系统中,用户空间、系统调用、虚拟机文件系统、缓存、文件系统以及存储之间的关系如下图:
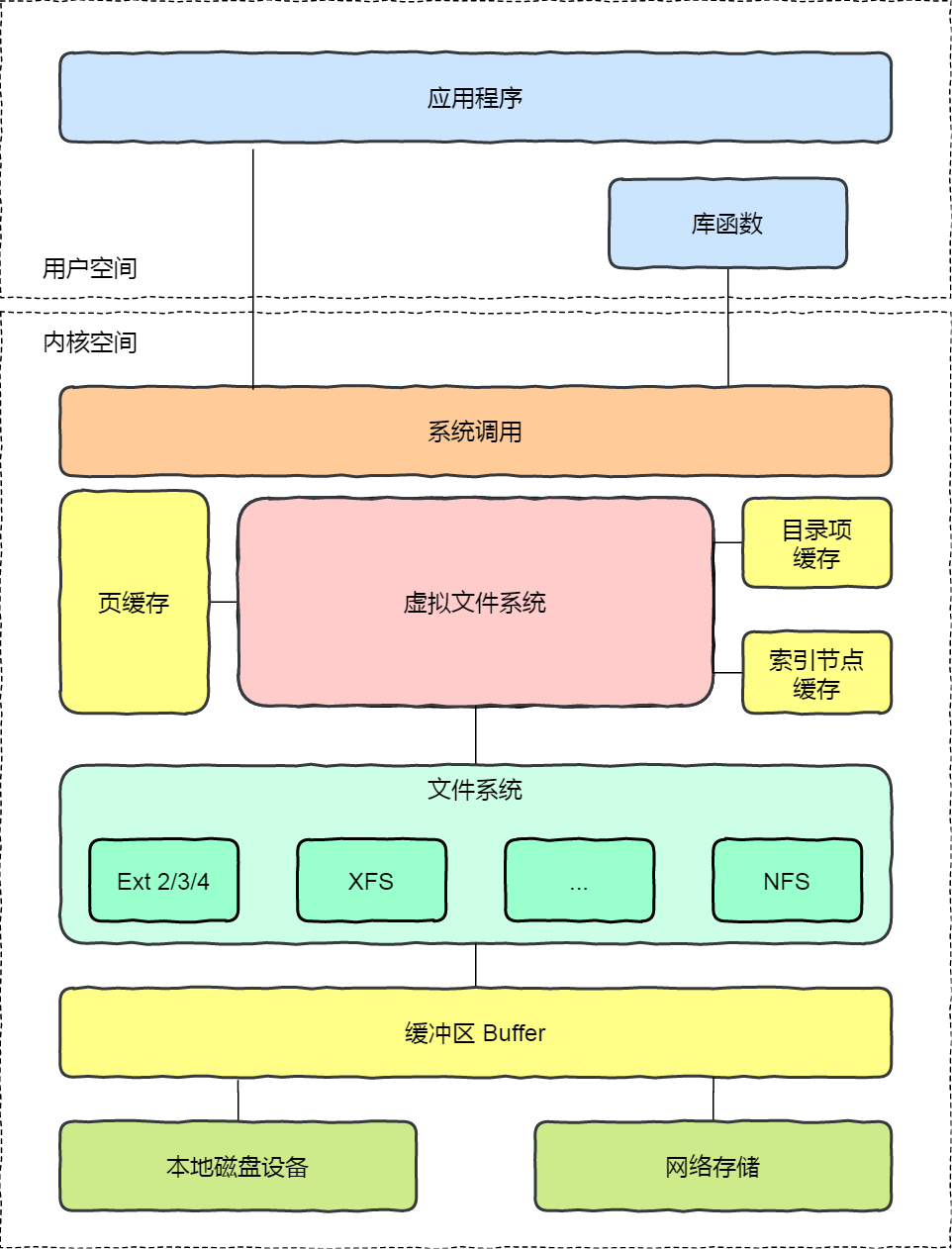
根据存储位置的不同,可以把文件系统分为三类:
- 磁盘的文件系统,它是直接把数据存储在磁盘中,比如 Ext 2/3/4、XFS 等都是这类文件系统。
- 内存的文件系统,这类文件系统的数据不是存储在硬盘的,而是占用内存空间,我们经常用到的 /proc 和 /sys 文件系统都属于这一类,读写这类文件,实际上是读写内核中相关的数据数据。
- 网络的文件系统,用来访问其他计算机主机数据的文件系统,比如 NFS、SMB 等等。
文件存储
---文件的数据是要存储在硬盘上面的,数据在磁盘上的存放方式,就像程序在内存中存放的方式那样,有以下两种:
- 连续空间存放方式
- 非连续空间存放方式
其中,非连续空间存放方式又可以分为「链表方式」和「索引方式」。
连续空间存放
连续空间存放方式顾名思义,文件存放在磁盘「连续的」物理空间中。这种模式下,文件的数据都是紧密相连,读写效率很高,因为一次磁盘寻道就可以读出整个文件。使用连续存放的方式有一个前提,必须先知道一个文件的大小,这样文件系统才会根据文件的大小在磁盘上找到一块连续的空间分配给文件。
所以,文件头里需要指定「起始块的位置」和「长度」,有了这两个信息就可以很好的表示文件存放方式是一块连续的磁盘空间。
注意,此处说的文件头,就类似于 Linux 的 inode。
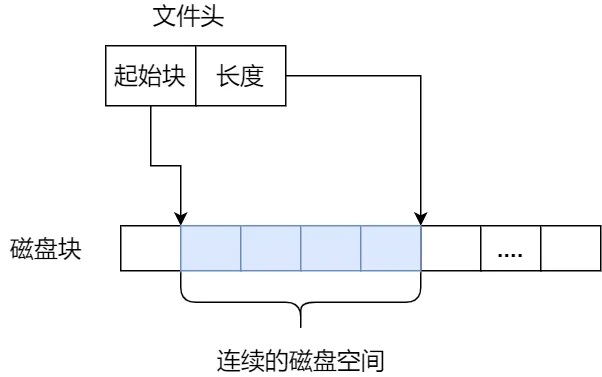
连续空间存放的方式虽然读写效率高,但是有「磁盘空间碎片」和「文件长度不易扩展」的缺陷。
如下图,如果文件 B 被删除,磁盘上就留下一块空缺,这时,如果新来的文件小于其中的一个空缺,我们就可以将其放在相应空缺里。但如果该文件的大小大于所有的空缺,但却小于空缺大小之和,则虽然磁盘上有足够的空缺,但该文件还是不能存放。当然了,我们可以通过将现有文件进行挪动来腾出空间以容纳新的文件,但是这个在磁盘挪动文件是非常耗时,所以这种方式不太现实。
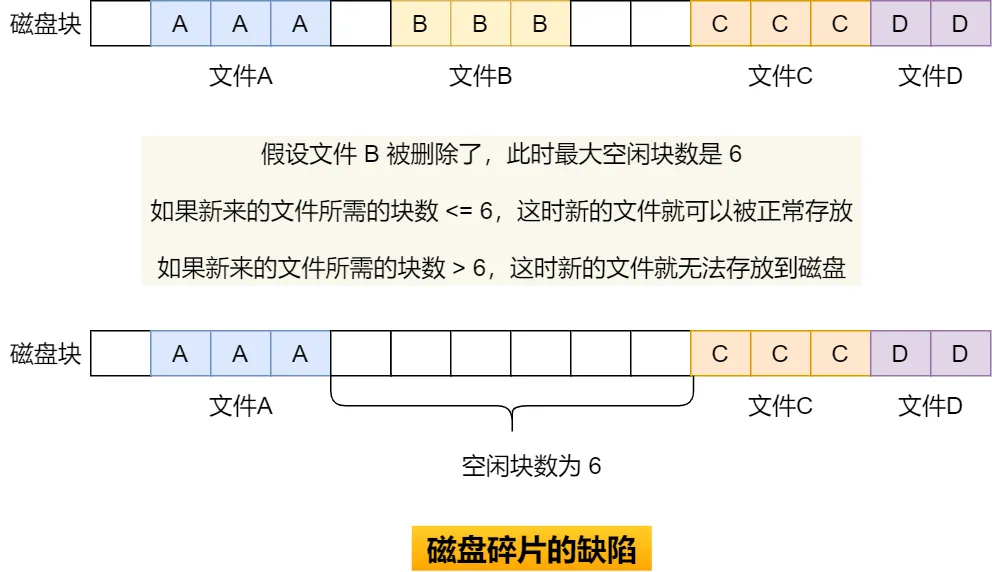
另外一个缺陷是文件长度扩展不方便,例如上图中的文件 A 要想扩大一下,需要更多的磁盘空间,唯一的办法就只能是挪动的方式,前面也说了,这种方式效率是非常低的。
那么有没有更好的方式来解决上面的问题呢?答案当然有,既然连续空间存放的方式不太行,那么我们就改变存放的方式,使用非连续空间存放方式来解决这些缺陷。
非连续空间存放方式
非连续空间存放方式分为「链表方式」和「索引方式」。链表的方式存放是离散的,不用连续的,于是就可以消除磁盘碎片,可大大提高磁盘空间的利用率,同时文件的长度可以动态扩展。根据实现的方式的不同,链表可分为「隐式链表」和「显式链接」两种形式。
文件要以「隐式链表」的方式存放的话,实现的方式是文件头要包含「第一块」和「最后一块」的位置,并且每个数据块里面留出一个指针空间,用来存放下一个数据块的位置,这样一个数据块连着一个数据块,从链头开是就可以顺着指针找到所有的数据块,所以存放的方式可以是不连续的。
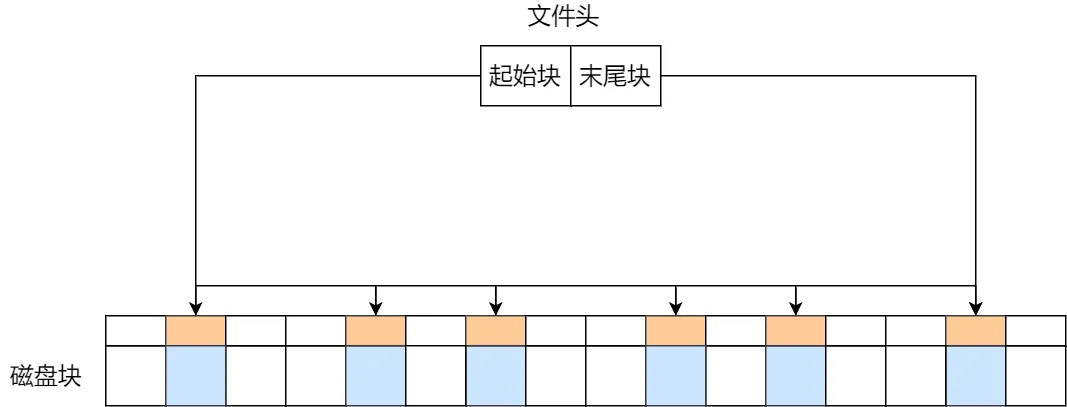
隐式链表
隐式链表的存放方式的缺点在于无法直接访问数据块,只能通过指针顺序访问文件,以及数据块指针消耗了一定的存储空间。隐式链接分配的稳定性较差,系统在运行过程中由于软件或者硬件错误导致链表中的指针丢失或损坏,会导致文件数据的丢失。
如果取出每个磁盘块的指针,把它放在内存的一个表中,就可以解决上述隐式链表的两个不足。那么,这种实现方式是「显式链接」,它指把用于链接文件各数据块的指针,显式地存放在内存的一张链接表中,该表在整个磁盘仅设置一张,每个表项中存放链接指针,指向下一个数据块号。
对于显式链接的工作方式,我们举个例子,文件 A 依次使用了磁盘块 4、7、2、10 和 12 ,文件 B 依次使用了磁盘块 6、3、11 和 14 。利用下图中的表,可以从第 4 块开始,顺着链走到最后,找到文件 A 的全部磁盘块。同样,从第 6 块开始,顺着链走到最后,也能够找出文件 B 的全部磁盘块。最后,这两个链都以一个不属于有效磁盘编号的特殊标记(如 -1 )结束。内存中的这样一个表格称为文件分配表(File Allocation Table,FAT)。
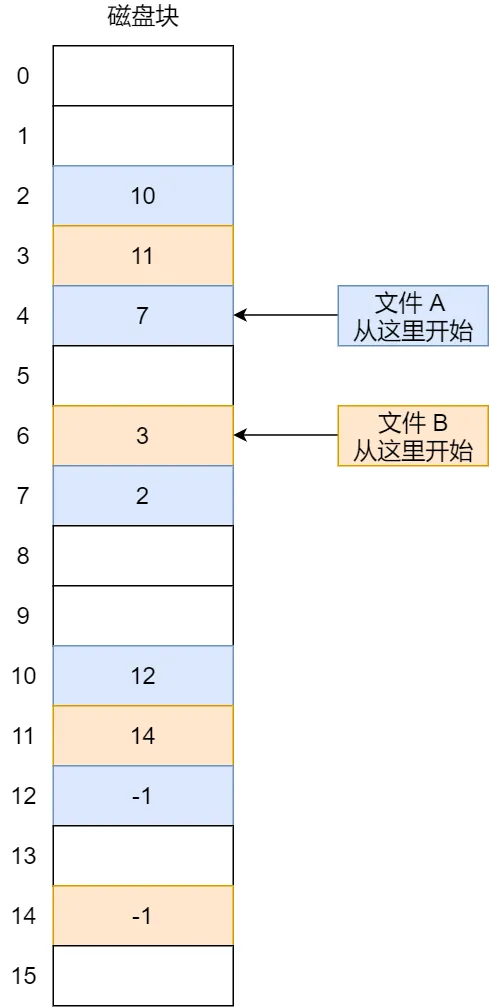
显式链接
由于查找记录的过程是在内存中进行的,因而不仅显著地提高了检索速度,而且大大减少了访问磁盘的次数。但也正是整个表都存放在内存中的关系,它的主要的缺点是不适用于大磁盘。
比如,对于 200GB 的磁盘和 1KB 大小的块,这张表需要有 2 亿项,每一项对应于这 2 亿个磁盘块中的一个块,每项如果需要 4 个字节,那这张表要占用 800MB 内存,很显然 FAT 方案对于大磁盘而言不太合适。
接下来,我们来看看索引的方式。
链表的方式解决了连续分配的磁盘碎片和文件动态扩展的问题,但是不能有效支持直接访问(FAT除外),索引的方式可以解决这个问题。
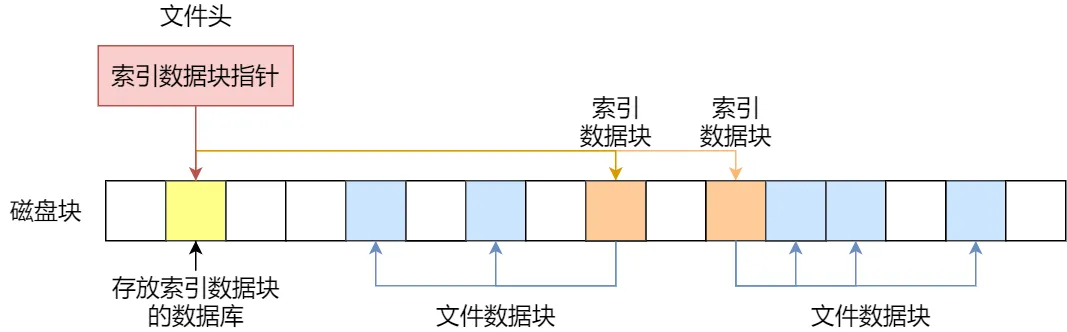
索引的实现是为每个文件创建一个「索引数据块」,里面存放的是指向文件数据块的指针列表,说白了就像书的目录一样,要找哪个章节的内容,看目录查就可以。
另外,文件头需要包含指向「索引数据块」的指针,这样就可以通过文件头知道索引数据块的位置,再通过索引数据块里的索引信息找到对应的数据块。
创建文件时,索引块的所有指针都设为空。当首次写入第 i 块时,先从空闲空间中取得一个块,再将其地址写到索引块的第 i 个条目。
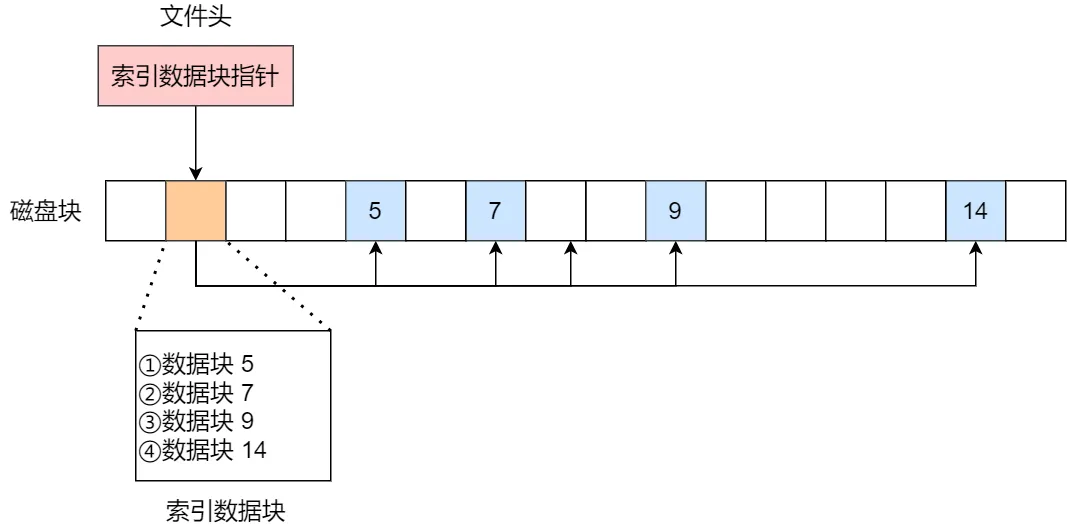
索引的方式
索引的方式优点在于:
- 文件的创建、增大、缩小很方便;
- 不会有碎片的问题;
- 支持顺序读写和随机读写;
由于索引数据也是存放在磁盘块的,如果文件很小,明明只需一块就可以存放的下,但还是需要额外分配一块来存放索引数据,所以缺陷之一就是存储索引带来的开销。
如果文件很大,大到一个索引数据块放不下索引信息,这时又要如何处理大文件的存放呢?我们可以通过组合的方式,来处理大文件的存。
先来看看链表 + 索引的组合,这种组合称为「链式索引块」,它的实现方式是在索引数据块留出一个存放下一个索引数据块的指针,于是当一个索引数据块的索引信息用完了,就可以通过指针的方式,找到下一个索引数据块的信息。那这种方式也会出现前面提到的链表方式的问题,万一某个指针损坏了,后面的数据也就会无法读取了。
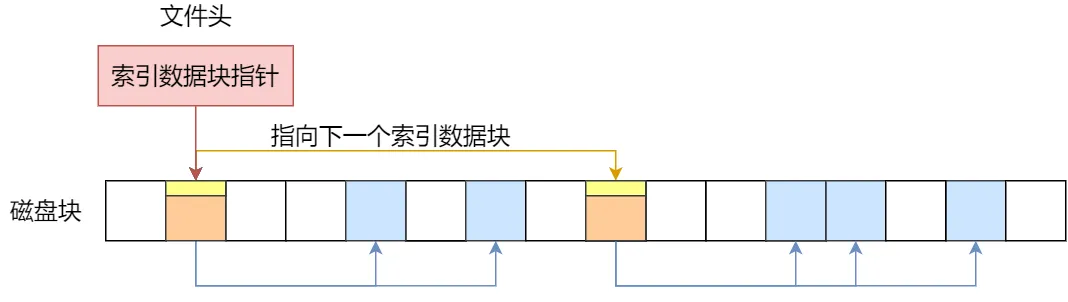
链式索引块
还有另外一种组合方式是索引 + 索引的方式,这种组合称为「多级索引块」,实现方式是通过一个索引块来存放多个索引数据块,一层套一层索引,像极了俄罗斯套娃。