
分布式存储
分布式文件系统
---介绍
分布式文件系统(Distributed File System,DFS)是指文件系统管理的物理存储资源不一定直接连接在本地节点上,而是通过计算机网络与节点(可简单的理解为一台计算机)相连;或是若干不同的逻辑磁盘分区或卷标组合在一起而形成的完整的有层次的文件系统。DFS为分布在网络上任意位置的资源提供一个逻辑上的[树形文件](https://zhida.zhihu.com/search?content_id=177552397&content_type=Article&match_order=1&q=%E6%A0%91%E5%BD%A2%E6%96%87%E4%BB%B6&zhida_source=entity)系统结构,从而使用户访问分布在网络上的共享文件更加简便。优势
分布式文件系统一般文件系统存储数据的方式数据分散的存储在多台服务器上集中存放所有数据,在一台服务器上特点[分布式网络](https://zhida.zhihu.com/search?content_id=177552397&content_type=Article&match_order=1&q=%E5%88%86%E5%B8%83%E5%BC%8F%E7%BD%91%E7%BB%9C&zhida_source=entity)存储系统采用可扩展的[系统结构](https://zhida.zhihu.com/search?content_id=177552397&content_type=Article&match_order=2&q=%E7%B3%BB%E7%BB%9F%E7%BB%93%E6%9E%84&zhida_source=entity),利用多台服务器分担负荷,利用位置服务器定位存储信息,不但提高了[系统的可靠性](https://zhida.zhihu.com/search?content_id=177552397&content_type=Article&match_order=1&q=%E7%B3%BB%E7%BB%9F%E7%9A%84%E5%8F%AF%E9%9D%A0%E6%80%A7&zhida_source=entity)、可用性和存取效率,还易于扩展,避免单点故障。传统的网络存储系统采用集中的服务器存放所有数据,到一定程度服务器会成为系统性能的瓶颈,也是可靠性和安全性的焦点,不能满足大规模存储应用的需要。分布式存储系统
---介绍
分布式存系统,是将数据分散存储在多台独立的设备上,从而解决传统的存储系统的容量和性能限制。所有如果存储服务器的可靠性和安全性无法满足大规模存储应用的需要,那么它就会成为分布式文件系统的性能瓶颈。分布式存储系统可以理解为多台单机存储系统各司其职、协同合作,统一的对外提供存储服务。
优势
分布式存储系统采用可扩展的系统结构,利用多台存储服务器分摊存储压力,利用位置服务器定位存储信息,它不但提高了系统的可靠性、可用性和存取效率,还易于扩展。分布式文件系统对比
---| 文件系统 | 适用场景 | 主要特性 | 优点 | 缺点 |
|---|---|---|---|---|
| HDFS | 大数据处理(如Hadoop) | 面向批处理,写多读少,数据分块存储,主从架构 | 高吞吐量,适合大规模数据分析 | 高延迟,不支持低延迟随机读写 |
| Ceph | 通用存储(对象、块、文件) | 基于CRUSH算法,无中心架构,强一致性 | 高可用性,扩展性强,支持多种存储方式 | 配置复杂,性能调优难度较高 |
| GlusterFS | 高性能存储、虚拟化平台 | 无元数据服务器,完全分布式,适合横向扩展 | 容易扩展,支持不同存储类型的集成 | 元数据操作效率低,适合小文件的性能一般 |
| MooseFS | 归档存储、备份系统 | 主从架构,数据冗余,支持故障自动恢复 | 简单易用,管理灵活 | 元数据服务器是单点瓶颈 |
| Lustre | 高性能计算(HPC) | 面向并行文件访问,专为高性能计算优化 | 性能极高,支持并行读写 | 部署复杂,对网络延迟敏感 |
| BeeGFS | 高性能计算、AI训练 | 分布式元数据管理,优化并行处理 | 部署灵活,元数据分布提高性能 | 社区支持较少,适配性有限 |
| IPFS | 分布式Web存储、内容分发 | 基于内容寻址,P2P架构,去中心化 | 去中心化,高扩展性,数据去重 | 不适合低延迟随机访问,实时性要求高的场景不适合 |
| MinIO | 对象存储,云原生场景 | 兼容S3协议,轻量化设计,支持Kubernetes集成 | 部署简单,高性能,支持对象级别的存储 | 不适合传统分布式文件访问场景,元数据存储依赖外部组件 |
| JuiceFS | 云原生分析,日志存储 | 基于对象存储的文件系统,可支持不同的云存储 | 性能较高,成本较低,支持弹性扩展 | 对元数据服务依赖较大,延迟可能受底层对象存储影响 |
分布式数据存储原理
---数据存储流程
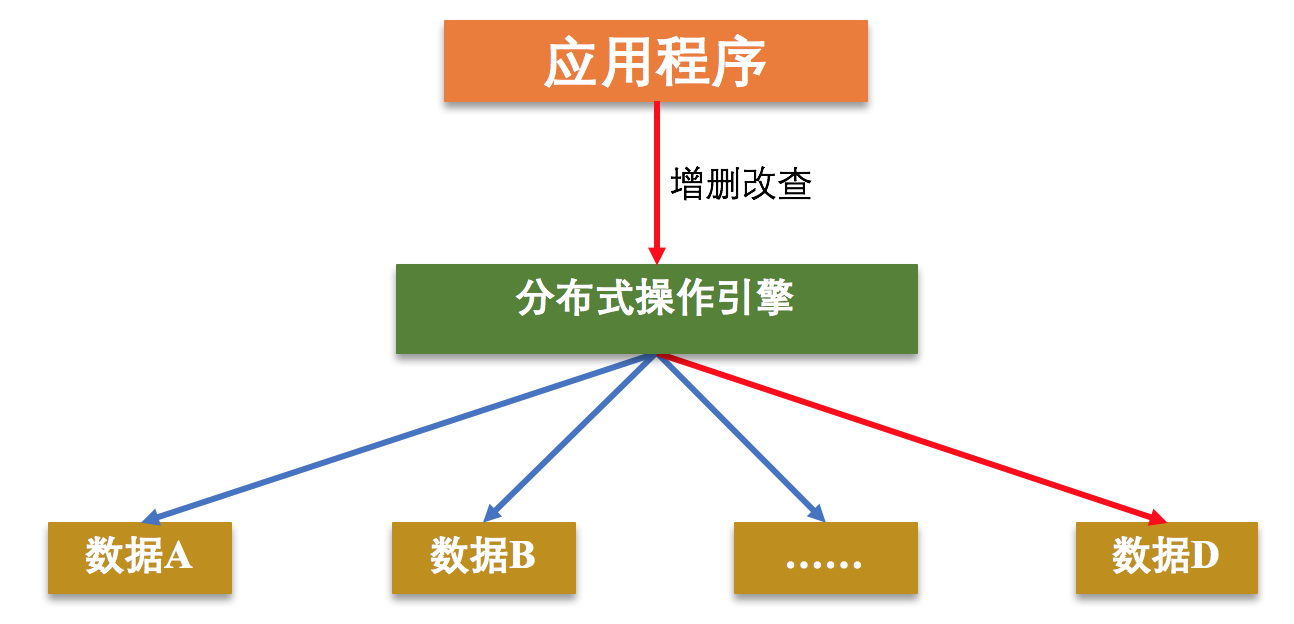在分布式存储引擎中存放文件属性信息以及每个文件对应的节点磁盘信息,在数据节点中存储具体的数据内容。
存储角色
当我们将数据存储到分布式系统上的时候,通过路由机制,将我们的请求转发给对应的存储节点上,所以存储元数据的节点我们称为 NameNode,而存储具体数据的节点称为 DataNode当我们存储的数据较大是,我们会先将存储的数据信息发送给元数据控制节点,然后控制节点进行数据拆分,实现并行存储的逻辑效果,每个数据块称为一个 shard。
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
